A search engine is a type of software that searches for information on the internet. It works by using a database or data set that contains information about web pages, such as their content, links to other pages, and metadata about the web page. The main goal of a search engine is to find the most relevant results for your query as quickly as possible.
What is Search Engine?
The search engine is a computer system or software that searches for information on the Internet, such as webpages and images. You can use a search engine to find specific information about people, places, and things. The search engine will provide the most relevant results to your search terms.
Nowadays, modern search engines are also called “semantic” or “natural language” because they can process words in their context rather than just matching them with predetermined keywords.
Types of Search Engine
Search engines are the most popular and useful tools on the Internet. They are very important for providing information to people and businesses. There are two main types of search engines that different methods can classify:
A)- Category wise Classification
1)- Category Search Engine
A category search engine is a search engine that organizes results by categories or topics. They provide results based on predefined categories.
The user submits a query, and the search engine provides links to articles that match their query. These categories may be health and fitness, business and finance, sports and athletics etc.
Yahoo’s home page is consider as category search engine, however, now search engines are moving from category search engines to general purpose search engines.
2) General-purpose Search Engines:
A general-purpose search engine is a web-based application that searches for information on the Internet using different criteria than a category search engine.
A general-purpose search engine does not provide results based on predefined categories. Instead, it provides results based on relevance to the user’s query and other factors such as time and date of publication or popularity among users.
The most popular general-purpose search engines are Google, Yahoo!, Bing,
B)- Classification Based on Content
1)- Content-Based Search Engine
Content-based search engines use information about the content to rank pages.
They rely on metadata like title, keywords, and description to determine which page is most relevant for a given query.
Famous content-based search engines are Google, Yahoo, Bing, Baidu, and DuckDuck Go.
These are designed to be intelligent and use natural language processing and artificial intelligence techniques. Though these search engines produce computational results, many responses would be written and audio-visual content on general topics.
2)- Computational search engines
Computational search engines rank pages based on their similarity to the query and are usually designed to handle mathematical and scientific queries. For example WolframAlpha

This search engine would be very helpful if you want to conduct research or find a response on a specific technical term.
C)- Scope and Size-Wise Classification
1)- Main Steam Search Engine
Search engines are a common way to find information on the Internet. Many types of search engines can be used to find different types of information.
There are three major mainstream search engines: Google, Bing, and Yahoo. These three search engines use crawlers to index web pages and then rank them based on their relevance to the user’s query.
2)- Vertical Search Engine
Vertical search engines are a type of search engine that provides search results for a certain topic or industry.
They provide a more focused set of results, which can be useful for specific industries.
This one is specifically designed to provide information and services related to a particular area, such as travel, sports, health care, finance, or the law.
3)- Private search engines
Private search engines are a type of search engine that is not accessible to the public.
Companies, organizations, or governments often use these search engines to restrict information on the Internet.
However, they provide a way for people with access to these search engines to find content without worrying about what information is available on the Internet.
Purpose of Search Engine
There are a few genuine purposes associated with search engines:
1)- Specific Query Specific Answer
The goal of a search engine is to help us find exactly what we’re looking for without having to scroll through pages and pages of results.
The relevancy component helps the search engine understand what a person is looking for. It considers keywords in the query and links on the page relevant to those keywords.
We expect a specific response to our query that should be accurate and to the point.
2)- Semantic Search Results:
The semantic search engine is a specialized web search engine that uses natural language processing and machine learning to extract meaning from the content on the web.
The semantic search engine is designed to make sense of the content’s meaning, not its form.
Semantic engines can process text, images, audio, and video to understand what it means.
3)- Find Out the Intent of the Search
Semantic search engines can draw inferences about what a person might be looking for on the web by looking at all of their searches over time and understanding their interests based on those searches.
They also consider what they have done on other websites like YouTube or Twitter to understand them as a person better.
We expect that search engines will grab our intent and show results accordingly. We seldom get disappointed by the results.
4)- Fresh Content Result:
The freshness component helps rank pages based on when they were last updated or first published online.
Search engine algorithms are vital to the success of any business. The algorithms are designed to provide fresh and up-to-date results. Search engines use a variety of factors to rank your site.
Everyone needs up-to-date, updated, and latest content. Therefore, we expect that Search Engine filter obsolete results.
How Search Engine Works
Search engines are not magical. Instead, they follow the rules to rank websites in the order they think is most relevant to the search query.

1)- Crawling
Google crawls the web to index its pages and rank them in search engine results.
This is how it works: A Google crawler, called a spider or crawler, visits websites, downloads their content, and follows all the links it can find.
The spider then analyzes the page to extract information like words on the page, meta tags, images, and more. This information is added to a database that makes up Google’s index of pages.
If you have a website that needs to be crawled by Googlebot, you can submit your site for crawling through Google Search Console.

2)- Indexing
Indexing is the process of adding a page to the Google search engine’s index. This means that Google can crawl or read your page and find out what your site is about.
Google indexes a website to determine its relevancy for any given query. The most important factor in determining relevance is the PageRank of the website.
The higher a site’s PageRank, the more likely it will be indexed by Google and rank well in SERPs (Search Engine Results Pages).
Google has developed a system for indexing web pages. It uses the following methods:
- Googlebot-Desktop
- Googlebot-Mobile
- Site maps and robots exclusion protocol (robots.txt)
3)- Ranking
Google ranks websites based on the number of backlinks and high-quality content.
The ranking system is based on a very simple algorithm called PageRank. It’s a measure of how important a website is in the eyes of Google.
An algorithm assigns pages with more links from other sites to be more important than those with fewer or no links.The higher your content’s quality, the higher it will rank on Google’s search engine results page (SERP).
Though Google is very tight-lipped regarding its Page Rank Factors, it gives clues and signals from time to time to educate website owners and SEO experts and decode them as per standard industry practices.

How to Check Crawled and Indexed Pages?
To check how many pages on a website are indexed, it is necessary to use Google’s Search Console. It is possible to find this information by navigating the Search Traffic section and clicking on Crawl Stats.
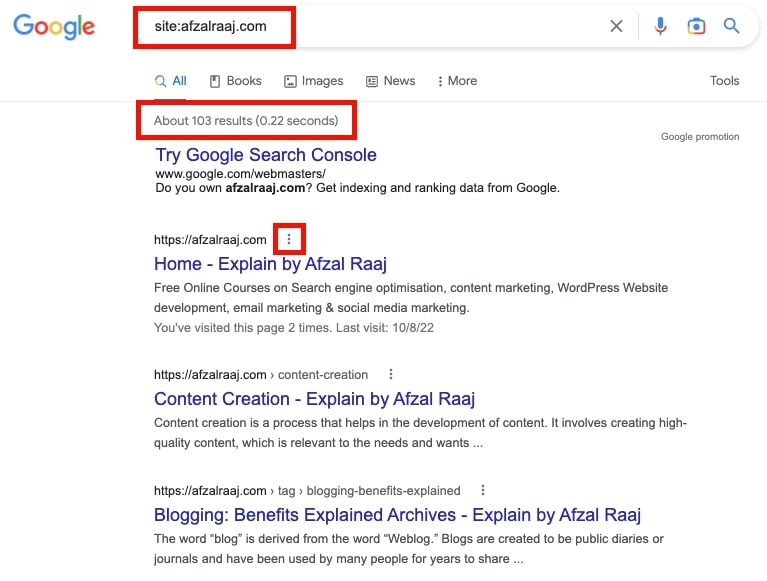
This will show all the pages crawled by Googlebot and indexed in their index. However, you can check the number of index pages by entering below code:
Site: website Name For example, www.afzalraaj.com
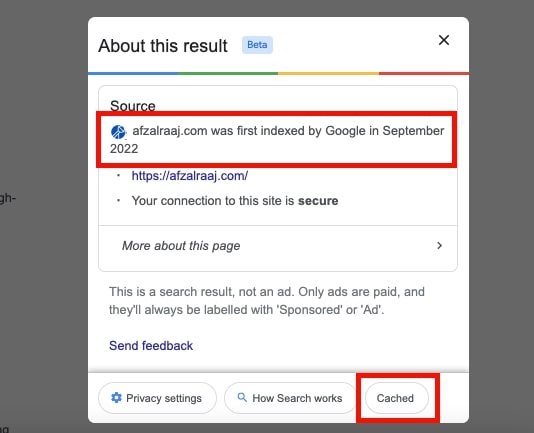
When you click on a result, there is a button to check the status of the last visit of Google crawler to your website and index the cache date and time.
Search Engine Ranking Factors
Search Engine Algorithm
On-Page SEO
On-page SEO is optimizing a website to rank higher in search engines. It includes several techniques, such as ensuring that all site pages are optimized for the same keyword phrases and that each page has unique, relevant Content.
We can do many things to improve our ranking in SERPS and make our Content more effective at grabbing visitors’ attention. There are two main types of on-page SEO: technical and Content.
Content Optimization refers to producing quality content as the customer needs nothing but Content.
Technical SEO includes mobile optimization, image optimization, user-friendly website structure, navigation, etc.
Off-Page SEO
Off-Page SEO is optimizing your website or blog for search engines by increasing its visibility and authority in the SERPs.
There are three major components of off-page SEO: link building, social media optimization, and content marketing.
Link building is acquiring backlinks from other websites to your site. It may include Guest Posting, Web 2. o blogging, and PBN creation. In addition, social media optimization promotes your website on social media channels such as Facebook, Twitter, and LinkedIn.
Finally, content marketing is a form of marketing that relies on creating high-quality content to attract an audience that will become customers.
Search Engine Content Quality Parameters
Page Quality Rating
Google Page Quality Rating is a new feature that Google has introduced to its search engine. This feature is designed to help the users know about the quality of the content on a particular webpage.
It also helps them know about the level of authority and trustworthiness of that webpage.
It includes the EAT content on YMYL topics and Quality Backlinks as an editorial reference from similar high-quality blogs and websites.
Needs Met Rating
The Google Needs Met Rating is a rating system that rates the relevance of a page to a user’s search query. The higher the Needs Met Rating, the more relevant the page is to the user’s search.
Google’s rollout needs to meet rating criteria in his famous Quality Rater’s Guidelines.
The more relevant your result is to a specific query, the more chances it gets a high rank in search results, as customers always expect perfectly matching and relevant results.
Engagement Metrics
People spend more time on their smartphones and tablets using these devices to make purchases. Google is following this trend by introducing an engagement metric in their search engine algorithm, which will rank websites according to how much time the visitor spends on the website.
It ranks websites according to how much time the visitor spends on the given website compared to other sites. The more engaged a visitor is, the higher ranking it will get from Google’s search engine algorithm.
Engagement metrics include bounce rate, Time on Page, conversion Rate, Pogo Sticking, and other factors. That is why UI and UX are key in modern SEO methods.
What is a Search Engine Result Page
A SERP is the list of web pages a search engine displays in response to a user’s query. The SERP usually includes a mix of links to the top ten websites for that search query and other web pages related to the search term.
The most popular search engine, Google, offers users their personalized SERP depending on their location and what they have searched for. It contains paid results, organic results, images, videos, location details, a shopping list, or any other relevant answer according to the intent of the search and query.

Concept of Crawl Budget
Search engines crawl the web to find new content and update their indexes. The crawl budget is the time a search engine spends crawling the web for new content.
The crawl budget is important because it affects how often search engines update their index and how fresh the information in those indexes is.
Crawl budget is also important because it can affect how quickly a site ranks in search engine results pages (SERPs).
In other words, Crawl Budget is the time a search engine spends indexing your website. It is measured in seconds per page. Therefore, the higher your crawl budget, the more often you will be crawled and indexed by search engines.
Concept of PageRank
PageRank is a link analysis algorithm developed by Google co-founder Larry Page. It assigns a numerical weighting to each hyperlink element based on the value and quality of the pages it leads to.
It was originally designed to measure the importance of web pages by considering the number and quality of links pointing to them.
Google PageRank measures the importance of a webpage in the Google search engine.
The higher the PageRank, the more important and authoritative a web page is. It is Google’s way of ranking pages so that users can find what they are looking for quickly and easily.
Concept of RankBrain
Google RankBrain is an artificial intelligence system that uses deep learning to process and rank web pages in Google Search. It was first introduced in October 2015.
It is a machine-learning system that can learn from how people interact with search results and improve its ability to guess which answer people are looking for.
RankBrain is not a ranking factor, but it helps Google understand which web pages are most relevant for specific queries. It also helps the search engine better understand synonyms and other related words.
How to add a website to Major Search Engines
You should add your website to major search engines for many reasons. The most obvious reason is that it may increase your website traffic. This can be done by submitting a sitemap of your site to Google and Bing.
You should also submit your site to the other search engines that are not as popular as Google and Bing but still have a decent amount of traffic.
Another reason is that it will make your site more visible on the web. Search engines will rank you higher in their search results if they know about you, which means more people will find you and visit your site.
How to add a website to Google
Google is one of the most popular search engines in the world. Billions of people use it daily to find anything they need online.
Google crawls and indexes web pages in its database to make them available for searches. When you submit your website, Google will index it and add it to its database.
When you submit your website, Google will index it and add it to its database. The process can take up to a few days, depending on how many pages your website has, how fast your server responds, or if any other site issues need to be fixed before you can start submitting it.
Google provides a tool that helps you submit your site so that they can index it and add it to their database faster than usual: https://www.google.com/webmasters/tools/submit-url.
Google is a fully automated search engine that uses web crawlers to explore the web constantly, looking for sites to add to our index; you usually don't even need to do anything except post your site on the web. In fact, the vast majority of sites listed in our results aren't manually submitted for inclusion, but found and added automatically when we crawl the web.
How to add a website to Yahoo
Yahoo is an internet search engine founded in 1994 by Jerry Yang and David Filo. Yahoo is a web portal that features content such as news, finance, sports, entertainment, and other information.
It’s easy to add a website to Yahoo. You need to follow the steps below:
1) Open your browser and go to “Yahoo.”
2) Click on the “Add Site” button
3) Enter your website URL
4) Click on the “Submit” button
How to add a website to Bing
Bing is a search engine from Microsoft. It is the second most popular web browser in the world. It has been around for more than ten years and has recently been updated to include new features and tools.
How to Add a Website to Bing:
Bing offers an easy way for website owners to add their site to their search engine results pages (SERPS). First, you must submit your site’s URL, and Bing will take care of the rest. You can also submit your website by using this link: https://www.bing.com/webmaster/SubmitSitePage?form=website&idx=1&utm_source=bing&utm_medium=webmaster&utm_campaign=website-submission-form.
You can also create a sitemap of your website so that it’s easier for Bing’s crawlers, which are automated programs that crawl websites, to find all the pages on your
How to add a website to Baidu
Baidu is a search engine that is widely used in China. It is the second most popular search engine in the world after Google. Its headquarters are located in Beijing, with offices in various other countries.
In this article, we will learn how to add a website to Baidu manually and automatically.
Manually:
1) Go to Baidu’s website by typing baidu.com into your browser address bar.
2) Type the URL of your website into the search bar on Baidu’s homepage and press enter or click “Search.”
3) If you want to add another site, you will have to type it again into the search bar and then press enter or click “Search.”
Automatically:
1) Sign up for a free account with Baidu’s partner program by clicking “Sign Up” on their homepage and following their instructions. You will be redirected to an
What is a Robots.txt file?
Robots.txt is a text file that can instruct web robots (web crawlers or spiders) about which parts of the website they should not enter. It is a way for web admins to control which pages on the website will be indexed by search engine robots and which pages will not be indexed.
The Robots Exclusion Standard, also known as the robots exclusion protocol, was created in 1994 by Martijn Koster, who wanted to create a standard that would allow site owners to keep their sites free of unwanted traffic while still allowing access for search engine spiders or crawlers.
Robots Meta Tag
Robots.txt files are used to control how search engine crawlers access the content of a website. In addition, robot meta tags are used to control how a webpage is indexed in search engines and whether it is archived.
The robots.txt file specifies which pages of the website can be crawled by web robots and which should not be accessed by them. It also provides information about the type of content that should be excluded from indexing, for example, if it is password-protected or contains sensitive information such as login credentials, credit card data, etc.
Robots meta tags are used in conjunction with HTML code to specify how search engines should index a page and whether it should be archived.
Index/Noindex tag
Do not show this page, media, or resource in search results. If you don’t specify this directive, the page, media, or resource may be indexed and shown in search results.
The
<meta name="robots" content="noindex">tag or directive applies to search engine crawlers. To block non-search crawlers, such asAdsBot-Google, you might need to add directives targeted to the specific crawler (for example,<meta name="AdsBot-Google" content="noindex">).
To prevent only Google from indexing your page, update the tag as follows:
<meta name="googlebot" content="noindex">
<meta name="googlebot-news"
content="nosnippet">
Using the robots meta tag
<!DOCTYPE html>
<html><head>
<meta name="robots" content="noindex">
(…)
</head>
<body>(…)</body>
</html>
For more, go through Google Search Central.
Follow, and No Follow Tags
Do not follow the links on this page. If you don’t specify this directive, Google may use the links on the page to discover those linked pages: These links became No Follow links:
<a rel="nofollow" href="https://cheese.
example.com/Appenzeller_cheese">
Appenzeller</a>
Mark links that are advertisements or paid placements (commonly called paid links) with the sponsored value. When you add this tag, it becomes a no-follow:
<a rel="sponsored" href="https://cheese.
example.com/Appenzeller_cheese">
Appenzeller</a>Links marked with these
relAttributes will generally not be followed. Remember that the linked pages may be found through other means, such as sitemaps or links from other sites, and thus they may still be crawled.
To comprehend the complete concept of what is the difference between Do-Follow and No-Follow Links, please click below: The concept of Do-Follow and No-Follow Backlinks
You don’t need to memorize these codes if you don’t have any interest in coding, just copy and edit, then paste.
Search Engine Working and Natural Language Processing
Search engines must make sense of natural language using Natural Language Processing (NLP). It is the process of understanding text in any language as if it were written in English.
NLP is an important part of search engine optimization because it helps search engines understand what a person is looking for when they type in keywords or phrases.
Search Engine Working and Artificial Intelligence
In recent years, search engines have been using Artificial Intelligence to help them do their job more efficiently. One of the ways AI is used in search engines is by identifying duplicate content.
Search engines use artificial intelligence to identify duplicate content and rank it accordingly. The algorithms are designed to identify common phrases, words, and sentences often repeated on a website.
The algorithm then calculates a score for each page based on how many common phrases it contains and how many unique words there are on each page. The pages with the highest scores will be ranked higher than those with lower scores.
This is an important feature for websites that want to avoid being penalized for having too much duplicate content.
Final Words
The search engine is a system that searches for specific information on the Internet. It is an application that indexes websites and other online content.
The search engine uses keywords, meta tags, and hyperlinks to find the desired information. Search engines are the most fundamental tool for any internet user. However, with so many search engines on the market, it can take time to figure out which is best for you.
Google RankBrain is an artificial intelligence system developed to increase the search engine’s ability to process and rank web pages.
Search engines are the number one method of finding information on the Internet. The problem is that most people need to learn how to get their website in front of search engines; this is where SEO comes in.
A)- Crawling
The search engine crawls or navigates through all the links on a website to find out what content it is linked to. Then, they use web crawlers or spiders to visit websites and pages.
A search engine crawls the web and indexes the content that it finds. First, the crawler follows all the links on a page and gathers more pages by following more links.
B)- Indexing
The search engine indexes all this information and stores it in its database, so it can be matched against queries and ranked accordingly.
Indexing is a process of analyzing and storing content for later use.
Search engines index billions of web pages, images, videos, news articles, books, and other types of content daily.
C)- Ranking
The ranking assigns each webpage its relevance to the search query entered by a user.
The content indexed and stored in the database then gets ranked based on how well it matches the user’s query.
Search engines use different software, and complex mathematical calculations called algorithms for ranking.
FAQs
The world’s largest search engine is Google. Google has a market share of around 88% in the United States and 90% in Europe. Google is the world’s most popular search engine.
According to StatCounter, as of June 2022, Google’s global search engine market share was at 91.88%, with Bing following at 3.19%, Yandex at 1.52%, Yahoo at 1.33%, Baidu at 0.76%, and DuckDuckGo at 0.64%.
The answer is yes. We can instruct the search engine to crawl our pages by using robots.txt file or by using a sitemap.
Robots.txt file: It’s a text file that contains instructions for the search engine crawlers, telling them which pages to crawl and which ones not to crawl.
Sitemap: It’s a file that lists all of the pages on your site and tells the crawler how to find them.
Search engines can find your pages without requesting to index it if you have a public URL. For example, if you publish your content on Medium, it will be indexed in Google search results.
If you have a personal website, you should add the site to Google Search Console and Bing so that they can find it and index it.
A sitemap is a file that provides an index to the content of a website. It can be created automatically by some web development tools, or it can be created manually by the site owner.
A sitemap helps crawlers and other search engine robots know what pages are on your site and where they can find them. It also helps people who want to link to your site find all of its content more easily.
There are many reasons why Google might send you a notification about an indexing error.
A common one is that the content was not crawled by Googlebot. This can happen if the content is not public, or if it’s blocked by robots.txt.
If you’re not sure what’s causing the issue, it can help to check your robots.txt file and make sure that all pages are public and crawlable. If they are, then contact Google for more information on how to fix the problem.
Local SEO is an important part of search engine optimization, and it is a great way to reach potential customers in your area.
It is a subset of search engine optimization that focuses on optimizing content for searches that are specific to the geographical location or region.
A search engine usually uses location information provided by the user or device, such as IP address, GPS data, and physical address.
The crawled but not indexed issue is a common problem faced by website owners. Search engine bots crawl the website, but the content is not indexed.
There are two main reasons for this issue
- Robots.txt: If your content is blocked from being indexed, you will face this issue.
- Mobile-friendly site: If your site is not mobile-friendly and Googlebot cannot crawl it properly, it might be crawled but not indexed.
- Duplicate content: If your content is plagiarized or poorly paraphrased, Google may crawl your website but won’t index pages.
To fix this problem, you need to ensure that there are no restrictions on crawling or indexing your website and that Googlebot can access it easily.
The algorithms in Google and Bing provide relevant results for queries. They work by learning from the user’s search history, preferences, and location. The algorithms can learn from users’ searches and provide relevant results to them.
For the algorithms to function properly, they need to be fed with data. Users generate this data as they search through their queries on the Internet. These data points can be provided from a variety of sources:
– Search engine logs
– User browsing history
– Webpages visited
– Location History
The first page of Google is the most popular for any search. This is because it has the most average traffic and is the page people are most likely to click on. This means that having a good ranking on Google’s first page is crucial to getting more traffic.
People are more likely to click on the first few results when searching for something. This means you will get more traffic if you rank well on Google’s first page. The first three results will get 70% of traffic.
The five basic steps of the search engine process are:
1. Crawling – The next step is to crawl your website and look for new content that needs to be indexed or updated links.
2. Indexing – The first step is to index the content on your website. This is done by a crawler that looks for meta tags, keywords, and other elements that help it understand what you’re trying to do with your website.
3. Ranking – The next step is ranking your website according to relevancy and importance for specific keywords or phrases after indexing.
4. Displaying – The final step in the search engine process is displaying results to the user.
Google is better than Bing for a variety of reasons. It is more accurate, has more features, and has a better search engine algorithm.
1) Google is more accurate: Bing does not have as many features as Google. Google’s search engine algorithm is also better than Bing’s, giving you the most relevant results possible.
2) Google has more features: Google also offers many other tools that make it much easier to use its search engine. For example, they offer voice recognition, translation, and even artificial intelligence-powered image-searching tools.
3) Google’s search engine algorithm is better: The algorithm determines what will show up in your search results based on your previous searches and browsing history. It also considers the popularity of certain terms or phrases to show you the most relevant results possible.
Google is one of the most popular search engines on the planet. It has been around for over a decade and continues to dominate the market. Google’s history can be used to understand how it works now.
Google’s history can be divided into four main stages: infancy, adolescence, adulthood, and older. Introduction: This essay will explore how Google has gone through these stages to comprehend how it has changed and developed over time.
Google was founded in 1998 by Larry Page and Sergey Brin as graduate students at Stanford University. They originally wanted to create a search engine that would allow users to find information on other websites and their website without having to go through any hoops or pay a fee for each search request.
The first version of Google didn’t even have a name but instead went by the company name “BackRub.” The first version of Google needed to be more advanced because they needed to learn what they were doing.
For example, Google was unable to crawl other websites without a program. In addition, at the time, internet websites were mostly text-based and not images.
The founders decided to keep their website as simple as possible to make it easier for people just starting with the Internet. Initially, the company was primarily based out of Stanford’s dorm rooms, where they had an office inside a closet.
Their office consisted of desks that were pushed together, and all three founders would sit in chairs on top of desks. The office would get very hot and stuffy, so the founders occasionally took a break from the building to roam around Palo Alto.
Google has been ranked as one of the world’s most valuable brands, according to BrandZ’s Top 100 Most Valuable Global Brands 2018 list. It is ranked first in its category with an estimated brand value of US$163.6 billion. In addition, Google received 114 awards covering categories such as design, innovation, engineering, and numerous others. In 2018, Google was ranked first in the Best Global Brands report.
Google has been developing a new product that will be released in 2023. It is an AI-powered system that will help people with everyday tasks, such as cooking or managing their schedules.
Sharing is Caring